
티스토리 뷰
ASCII, Unicode, UTF-8
ASCII: 글자당 1 byte
Unicode: 글자당 4 byte
UTF-8: 공간 낭비를 막는다. 글자당 1~4byte 사이로 필요한 byte만큼 사용한다.
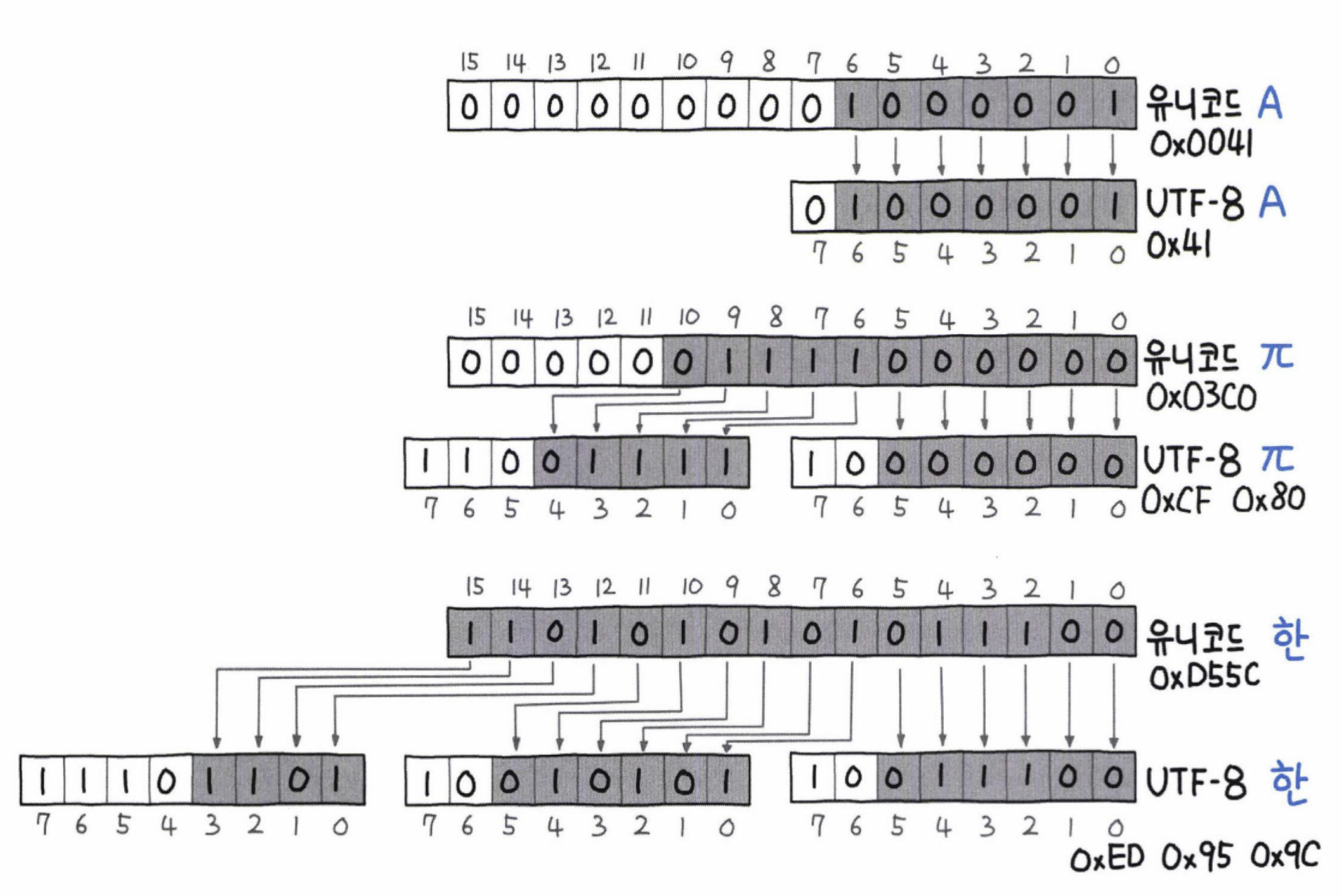
UTF-8이 공간 낭비를 막는 방식
UTF-8이 공간 낭비를 막는 방식에 대해서 살펴보자!
결론적으로 기억할 사실은 UTF-8은 US-ASCII와 호환성을 가졌다는 사실이다.
첫 바이트의 맨 앞 비트가 0이면 1바이트 문자, 10인 경우 특정 문자의 중간 바이트, 110인경우 2바이트, 1110인경우 3바이트, 11110인경우 4바이트 인걸로 문자 바이트의 길이를 인식할 수 있다.
ASCII는 128개의 글자가 있다. 그러므로 2^7 -> 7 bit로 표현 가능하다. 1byte에 store 할 수 있는 것이다!
[출처]
파이썬 알고리즘 인터뷰 (박상길 저) p 164
'PL > Python' 카테고리의 다른 글
| [Python] linked list의 runner 기법 (0) | 2022.01.05 |
|---|---|
| [Python] is와 ==의 차이 (0) | 2022.01.05 |
| [Python] 타입을 호환하는, Generics (0) | 2021.12.29 |
| [Python] for문을 작성하는 3가지 방법 (0) | 2021.12.29 |
| [Python] 설치 PATH 찾기 (0) | 2021.12.28 |