

 [PL][WIP] 파이썬으로 Lexical Analyzer 만들기
[PL][WIP] 파이썬으로 Lexical Analyzer 만들기
과제라서 하게 되었다.... 내가 만들어야 하는건 사칙연산과 괄호, 정수를 지원하는 lexical analyzer였다. 그림에서 보이다싶이 lexical analyzer는 입력받은 코드를, syntax analyzer ( parser)에게 lexical unit으로 쪼개서 전달해야 한다. 그리고 symbol table을 만들어야 한다. 물론 모든 문법을 지원하면 좋겠지만 내가 만든 Lexical analyzer에서 지원해야 문법은 다음과 같았다. → → | → → → | ε → → | ε → | | → any decimal numbers → any names conforming to C identifier rules → := → ; → + | - → * | / → ( → ) 예를 들어 보자! operan..
딥러닝을 처음 공부할때 나를 정말 힘들게 했던 에러다...하지만 차근차근 생각해보니 쉽게 해결할 수 있는 에러였다. 먼저, CPU와 GPU는 엄연히 다른 기기이다. 메모리 공간이 분리되어 있기 때문에 CPU에 있는 텐서와 GPU에 있는 텐서를 비교할 수 없는 것이다. 그래서 우리가 텐서끼리의 연산을 할 때 반드시 같은 기기인지 확인을 해야한다. 1. 텐서끼리 같은 기기에 있는지 확인해보자. 텐서가 CPU에 있는지 GPU에 있는지 확인하기 위해서 is_cuda()함수를 사용한다. # CPU에 있는 텐서 t = torch.randn(2,2) t.is_cuda # returns False # GPU에 있는 텐서 t = torch.randn(2,2).cuda() t.is_cuda # returns True Fa..
chapter 4의 내용이다! 정규 언어의 Closure 정규 언어에 대한 주요한 질문들 비정규 언어 판별하기 - pigeonhole principle(비둘기집 원리) 예시로 살펴보자! L = {a^n b^n: n>=0} 이면 L은 정규언어일까? (예제 4.6) 여기에 해당하는 언어는 L = { ƛ, ab, aabb, ... } 등이 있을 것이다. 이 문제를 귀류법으로 접근하면, L이 regular language라면 DFA M = {Q, {a,b}, 𝛿, q_0, F}가 존재할 것이다. i=1,2,3..일 때 𝛿*(q_0, a^i)를 생각하면 i는 무한대로 많을 것인데 M에는 state개수가 유한하다. 그렇다면, 𝛿*(q_0, a^n) = q 𝛿*(q_0, a^m) = q인 서로 다른 n, m이 존재하..
 [Automata][WIP] 정규 언어와 정규 문법
[Automata][WIP] 정규 언어와 정규 문법
이번에는 chapter 3의 내용을 다루려고 한다!.! 정규 표현식 ( Regular Expression ) 정규표현식은 알파벳, 덧셈(+), 곱셈(·), 제곱(*)으로만 이루어져 있다. 덧셈 a+b는 a랑 b로 이루어진 집합에서 뽑아서 쓰는 것이다. a+b = {a, b} 라고 생각하자. 제곱 (a+b)*는 ƛ, a, b, aa, ab, ba, bb, aaa ,,, 등이다. 순서 상관 없다! a*는 0개 이상 반복이다. 예1 ) r = (a+b)*(a+bb) 예2) r = (aa)*(bb)*b 정규 표현식과 정규 언어의 관계 정규 문법 ( Regular Grammar ) 예1) V_0 -> aV_1 V_1 -> abV_0 | b V_0이 시작임
이번 포스팅에서는 Chapter 5에 나오는 내용들을 다뤄보려고 한다! 변수의 6가지 속성 1) names 2) address 3) value 4) type 5) lifetime 6) scope 1) names 대소문자를 가리는가? (Case Sensitivity) C 기반 언어들에서는 대소문자를 가리는데, Readability & Writability 가 안좋아 진다. 특수어 keyword: 특정 문맥에서만 특수 의미를 가짐. ( ex: 변수 이름 ) reserved word: 사용자 정의 이름으로 사용 불가능 ( ex: int, float, ... ) 예약어가 너무 많은 언어는 쓰기 힘들다 ( ex: COBOL의 length, bottom, count 등 ) 길이 너무 짧으면 함축적일수가 없다! C9..
 [ML] PyTorch 기본 함수들
[ML] PyTorch 기본 함수들
텐서(tensor)는 배열(array)이나 행렬(matrix)과 매우 유사한 특수한 자료구조입니다. PyTorch에서는 텐서를 사용하여 모델의 입력과 출력뿐만 아니라 모델의 매개변수를 부호화(encode)합니다. GPU나 다른 연산 가속을 위한 특수한 하드웨어에서 실행할 수 있다는 점을 제외하면, 텐서는 NumPy의 ndarray와 매우 유사합니다. 만약 ndarray에 익숙하다면 Tensor API를 바로 사용할 수 있습니다. list -> tensor data = [[3,5], [10,5]] x_data = torch.tensor(data) numpy array -> tensor np_array = np.array(data) x_np = torch.from_numpy(np_array) tensor -..
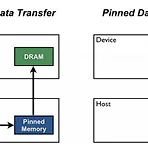 [ML] PyTorch Dataset, DataLoader
[ML] PyTorch Dataset, DataLoader
Dataloader DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None) Dataloader class는 batch기반의 딥러닝모델 학습을 위해서 mini batch를 만들어주는 역할을 한다. dataloader를 통해 dataset의 전체 데이터가 batch size로 slice된다. 앞서 만들었던 dataset을 input으로 넣어주면 여러 옵션(데이터 묶기, 섞기, 알아서 병렬처리)을 통해 batch를 만들어준다. 서버에서 돌릴 때..
먼저 시도해볼 방법 git remote set-url origin https://YOURUSERNAME@github.com/USERNAME/REPOSITORY.git 이걸로 remote url을 바꿔본다. 안된다면 밑의 방법을 사용해보자! SSH Key를 이용해서 하는 방법!!! 1. 아래 명령어로 ssh key 생성 $ ssh-keygen 나머지 줄은 엔터 쳐서 생성하면 2. ssh-key 복사 (id_rsa.pub 확인) $ cat ~/.ssh/id_rsa.pub * 꼭 .pub을 써줘야하는 것 같다. 안써주니까 다른 파일이 나왔다! 3. github 키 등록 profile>settings>SSH and GPG keys > New SSH key 클릭 ========== +) profile이 없다는 메..