
티스토리 뷰
Intro
PCA는 데이터가 여러 component(dimension)를 갖고 있을 때,
1) 가장 grouping하기 좋은 특징을 찾아 clustering을 하고 싶을 때
2) 여러 component 중 데이터를 대표하는 component를 구하고 싶을 때
3) dimension을 축소하고 싶을 때
등등의 경우에 쓴다고 생각하면 된다. component 중 가장 데이터를 대표하는 특징을 '주 성분(Principle Component)' 이라고 부른다.
Step-By-Step
1. 모든 data를 원점이 중심이 되게 옮긴다.
2. data들로 covariance matrix를 구한다.
3. covariance matrix의 Eigenvalue, Eigenvector들을 구한다.
4. Eigenvalue들을 크기가 큰 순으로 나열한다.
5. 각각의 Eigenvalue에 대응하는 Eigenvector을 찾는다. 이 Eigenvector가 Principal Component이다.
step1부터 하나씩 알아보도록 하자!
step1. 모든 data를 원점이 중심이 되게 옮긴다.
이렇게 축에서 거리가 멀었던 data들을

중심을 기준으로 이동해줄 수 있다.
step2. data들로 covariance matrix를 구한다.
covariance matrix(공분산 행렬)이 뭔지, 어떻게 구하는지 차근차근 알아보자.
먼저 '분산'부터 생각해보자.

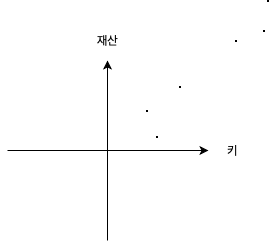
분산은 축이 하나뿐인 data가 얼마나 퍼져있는 지를 나타낸 값이었다.
위쪽의 그림의 data에는 키가 비슷한 사람들이 있었고, 아래 그림의 data에는 키가 다양했다.
위보다 아래의 분산이 클 것이다.
그런데 어떤 사람들은, 여러 축에 대해서 분포를 구하고 싶어졌다.

그림 1처럼 x와 y가 비례하는걸 보이고 싶다면??
반대로 그림 2처럼 x와 y가 반비례하는걸 보이고 싶다면??
이를 설명하기 위해서 '공분산'이라는 개념을 도입했다.

각각의 점(데이터)에 대해서, x, y를 평균과 차이를 구해서 곱한 후 모두 더해준 값이 +이면 비례 관계, -이면 반비례 관계라고 생각할 수 있다.
실제로 해보면 그림1은 +이고 그림2는 - 값의 covariance가 나올 것이다.
어렵지 않으니까 꼭 해보고 감을 잡도록 하자.

그런데, 현재 covariance는 축이 2개인 data만 가능했다.
축이 3개 이상인 경우를 설명하기 위해서 matrix로 확장했다.

이렇게!!
여기까지 이해가 어렵지 않을 것이라고 생각한다.
* 추가! 데이터의 비례, 반비례를 보이는 방법은 공분산 말고도 다양하다.
공분산은, data의 scale에 따라서 data의 분포 모양이 같더라도 공분산의 값은 차이가 클 수도 있다.
따라서, '상관계수(Correlation)'을 사용해서 분산을 나타내기도 한다.
step3. covariance matrix의 Eigenvalue, Eigenvector들을 구한다.
Eigenvalue, Eigenvector 역시 차근차근 하나씩 해 보자.
Eigen-이라는 수식어는 독일어로 '고유의' 라는 수식어이다.
따라서, Eigenvalue, Eigenvector은 matrix의 "고유의" 벡터, "고유의" 값이다.
matrix가 다르다면 Eigenvalue와 Eigenvector도 다를 것이다.
(참고로, Eigenvalue와 Eigenvector은 정방행렬에서만 구할 수 있다.)
Eigenvalue과 Eigenvector는 그 matrix의 중요한 성질 중 하나이다.
그렇다면 Eigenvalue와 Eigenvector을 어떻게 구할까?
정의에 의하여, 내 정방 matrix가 A일 때,
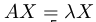
을 만족하는
X: Eigenvector
ƛ: Eigenvalue
이다.
ƛX 항을 좌변으로 넘겨보자.

X = 0이거나, A=ƛI 이면 방정식을 풀 수 있을 것 같아 보이는데,
X = 0 인 해는 우리가 원하지 않는 해이다..
(중학교 때 일차방정식 ax=bx 값 중에서 x=0은 우리가 찾는 해가 아닌 느낌이랄까..)
따라서 A = ƛI 인 람다부터 찾아보겠다.
이는 'Determinant'를 구해서 찾는다.

람다는 한개가 나올 수도 있고 여러개가 나올 수도 있다.
AX = ƛX에다가 찾은 람다 값을 각각 넣어서 나오는 모든 X 벡터들이 Eigenvector이다.
어려울 수 있으니, 예제를 통해서 감을 잡아보자.
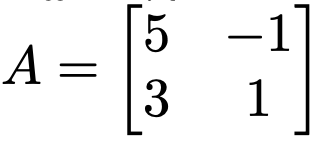
Q ) A matrix의 Eigenvector와 Eigenvalue는?
A ) 일단은 Determinant를 찾자.
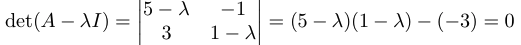
이차방정식을 풀었더니 2, 4가 나왔다.

AX = ƛX에다가 찾은 람다 값을 각각 넣어서 나오는 모든 X 벡터들이 Eigenvector이다.

따라서 Eigenvalue는 2, 4, Eigenvector는 (1,3), (1,1)이다. 여기까지는 어렵지 않게 따라왔길 바란다...🙏
step4. Eigenvalue들을 크기가 큰 순으로 나열한다.
말 그대로! 람다의 크기 순으로 나열해준다.
step5. 각각의 Eigenvalue에 대응하는 Eigenvector을 찾는다. 그 중 첫번째 Eigenvector가 Principal Component이다.
따라서 위 예제로 보면 (1,1) 이 Principal Component가 된다.
??근데 왜 Eigenvector가 Principal Component인데???
가장 중요하면서도 가장 어려운 질문이다.
활용) 영상 인식, 통계 데이터 분석, 데이터 압축(차원 감소), 노이즈 제거 등등...에서 쓰인다고 한다.
* dimension reduction을 PCA로만 할 수 있는 것은 아니다. > 더보기
dddd
dd
dd
'Math > 수치해석' 카테고리의 다른 글
| [수치해석][WIP] Jacobi Method, Gauss-Seidal Method (0) | 2021.12.15 |
|---|