
브루트포스로 풀 걸 그래도 생각하는 과정이 할만했던 것 같다... top을 정의해서 top이 6, 16, 26 처럼 6이 한개이면 last6 = 1, 66, 266처럼 6이 2개이면 last6 = 2.. 이런식으로 커지고 top6가 1이라면 안에서 10번 loop를 돌아서 {top}66{i} 를 프린트 해준다. 6660부터 6669까지 프린트 할 수 있는 이유이다. 마찬가지로 top6가 2이라면 안에서 100번 loop를 돌아서 {top}6{i} 를 프린트 해준다. 66600부터 66699까지 프린트 할 수 있는 이유이다. 이런식으로 top6가 5일때까지 구해줬다. import sys N = int(sys.stdin.readline()) count = 1 top = 0 last6 = 0 while cou..
m_bin = int(input(), 2) print(oct(m_bin)[2:])
서론 중국인의 나머지 정리(Chinese remainder theorem; CRT)는 중국의 5세기 문헌인 『손자산경(孫子算經)』에는 나오는 문제로, 내용은 다음과 같다. 3으로 나누었을 때 2가 남고, 5로 나누었을 때 3이 남고, 7로 나누었을 때 2가 남는 수는 무엇인가? x = r1 (mod n1) x = r2 (mod n2) ... x = rk (mod nk) 이고 N = n1 * n2 * ... * nk 라고 하자. mi는 mi * (N/ni) = 1(mod ni)를 계산해서 구한다. 일반해는 x = m1 (N/n1) + m2 (N/n2) + ... + mk (N/nk) mod N 배경 지식 곱셈의 역원 구하기 출처 https://namu.wiki/w/중국인의%20나머지%20정리
비트를 지도처럼 쭉 늘여놓아서 비트맵이다. 데이터를 비트 단위로 처리하기 위해서 long 배열로 할당한 자료형 C의 모든 자료형은 최소 단위가 byte라서, 실제로는 8의 배수의 bit로 나오게 된다. 기본 연산 OR can be used to set a bit to one: 11101010 OR 00000100 = 11101110 AND can be used to set a bit to zero: 11101010 AND 11111101 = 11101000 AND together with zero-testing can be used to determine if a bit is set:11101010 AND 00000001 = 00000000 = 011101010 AND 00000010 = 00000010..
XArray는 매우 큰 포인터 배열처럼 동작하는 추상 데이터 타입(abstract data type) 입니다. 해시와 크기 변경 가능한 배열을 모두 만족 시킵니다. 해시와 다른 점이라면, 캐시 친화적인 방식으로 위치 이동(이전, 다음)을 효율적으로 할 수 있습니다. 크기 변경 가능한 배열과 다른 점이라면, 배열의 크기를 증가 시키기 위해서 데이터를 복사 하거나 MMU 매핑을 변경할 필요가 없습니다. 양방향 연결 리스트(doubly-linked list) 보다 메모리 효율성이 좋고 병렬화 가능하며 캐시 친화적입니다. 또한 RCU의 장점을 활용하여 락킹없이 조회 작업을 수행합니다. 위와 같이 XArray는 많은 장점을 가지고 있는 자료구조 입니다. 하지만 XArray에는 몇가지 특징(장단점)들이 있습니다. ..
맵은 hash라고도 부른다. 배열이나 딕셔너리와 관련있는 key-value 형태의 저장소이다. 키 값은 트리에서 중복되지 않는다. [Map의 종류] Hash Map : 중복 허용하고 순서 보장 x Linked Hash Map : map에 있는 원소들의 linked list를 유지한다 Hash Table : Hash Map보다 느리지만 동기화 지원 Tree Map : 오름차순 정렬을 하면서 저장한다. 파이썬의 dictionary 또한 hashmap으로 되어 있다.
항상 exit(0)으로 끝내야함!!

자료구조 시간에 배운 binary search tree를 알아야 이해할 수 있는 개념이다!! (자신의 왼쪽 트리에는 현재보다 작은거, 오른쪽 tree에는 현재 값보다 큰 값이 왔던 tree이다. ) (inorder traverse를 하면 오름차순으로 정렬된 값을 얻을 수 있다) red black tree는 binary search tree중 balance가 맞는 tree이다. (self-balanced라고 한다) red black tree의 조건 1. root node는 black 2. 모든 external node는 black 3. red의 자식은 black 4. 모든 leaf node에서 root node까지 가는데 만나는 black의 개수는 같다. 처음 root는 black으로 만들고, 자식으로는 ..
동기화의 필요 이유 Forks and Joins : fork point에 일이 도착하면, n개의 sub-job으로 쪼개져서 n개의 task로 수행된다. n개의 task가 모두 수행될때까지 기다렸다가 끝난다. Producer-Consumer: producer가 정보를 만들어서 전달해주기 전까지 consumer은 기다려야 한다 Exclusive use resources: 여러개의 process가 resource에 의존적일 때, 모두 같은 시간에 접근해야 한다. -> 동시성 감소? 1. Lock Lock을 해서 특정 코드 영역에 대한 상호 배타성을 보존하는 방식이다. lock문제를 해결하기 위한 방법으로는 크게 3가지가 있다. 1. 소프트웨어적인 방법 ex) 피터슨 알고리즘 2. atomic instructi..
 [자료구조] 래딕스 트리(Radix Tree) (기수 트리)
[자료구조] 래딕스 트리(Radix Tree) (기수 트리)
* radix tree 는 radix trie, compact prefix tree라고도 부른다 * radix tree역시 binary search tree를 알아야 한다. 개인적으로는 red black tree 글을 작성하고 이 글을 작성했으므로 red black tree 글을 먼저 보고 오는걸 추천한다. radix tree는 binary search tree, red black tree처럼 왼쪽 < 자신 < 오른쪽 노드의 크기로 배치된다. 그러나 radix tree는 트리의 균형을 맞추는 방식이 조금 다르다. red-black tree는 색상값 데이터를 가지고 노드를 좌우로 회전시키면서 균형을 맞췄다. 그러나 radix tree는 이런 회전 작업 없이도, 키 값에 따라서 0이면 왼쪽, 1이면 오른쪽으..
https://gmnam.tistory.com/226
1. namespace란? 여러명이 서로 나누어 프로젝트를 개발하는 경우 오픈소스 여러개를 합치는 경우 이름이 충돌 나는 경우를 많이 겪어봤을 것이다. 그래서 생긴것이 namespace! namespace SweetDev { } namespace 안에서 생성된 변수, 함수는 그곳에서만 사용된다. 2. std란? C++표준에서 정의한 namespace중에 한 가지이다. cout, cin, endl등 자주 쓰는 함수들이 들어있다. std::cout을 매번 쓰는게 귀찮다면 using 명령어를 사용해서 해결할 수 있다. using std:: cout; using namespace std; 둘중에 하나로...
 NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running. 오류 해결하기
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running. 오류 해결하기
갑자기... 컴퓨터를 강제종료하면 이런 오류가 생길 수 있다고 한다....ㅠㅠㅠㅠ 1. nvidia-smi 해당 오류가 나온다. 2) apt --installed list | grep nvidia-driver 3) sudo apt remove nvidia-driver- sudo apt autoremove 4) sudo apt-get install nvidia-driver- sudo reboot now 하면 잘 되는 모습을 볼 수 있따!! * 안될 때 apt-get update하고 다시 하니까 됐다...
1) sudo ubuntu-drivers autoinstall 2) sudo nano /etc/default/grub #GRUB_GFXMODE=640x480 -> GRUB_GFXMODE=1920x1080 sudo update-grub sudo reboot +)혹시나 둘 다 안되는 사람이라면 https://sweetdev.tistory.com/951 이 방법을 확인해서 해결하는것도 좋아보인다!! 난 이렇게 해결했다 :) [출처] https://askubuntu.com/questions/441040/failed-to-get-size-of-gamma-for-output-default-when-trying-to-add-new-screen-res Failed to get size of gamma for outpu..

 [PL][WIP] 파이썬으로 Lexical Analyzer 만들기
[PL][WIP] 파이썬으로 Lexical Analyzer 만들기
과제라서 하게 되었다.... 내가 만들어야 하는건 사칙연산과 괄호, 정수를 지원하는 lexical analyzer였다. 그림에서 보이다싶이 lexical analyzer는 입력받은 코드를, syntax analyzer ( parser)에게 lexical unit으로 쪼개서 전달해야 한다. 그리고 symbol table을 만들어야 한다. 물론 모든 문법을 지원하면 좋겠지만 내가 만든 Lexical analyzer에서 지원해야 문법은 다음과 같았다. → → | → → → | ε → → | ε → | | → any decimal numbers → any names conforming to C identifier rules → := → ; → + | - → * | / → ( → ) 예를 들어 보자! operan..
딥러닝을 처음 공부할때 나를 정말 힘들게 했던 에러다...하지만 차근차근 생각해보니 쉽게 해결할 수 있는 에러였다. 먼저, CPU와 GPU는 엄연히 다른 기기이다. 메모리 공간이 분리되어 있기 때문에 CPU에 있는 텐서와 GPU에 있는 텐서를 비교할 수 없는 것이다. 그래서 우리가 텐서끼리의 연산을 할 때 반드시 같은 기기인지 확인을 해야한다. 1. 텐서끼리 같은 기기에 있는지 확인해보자. 텐서가 CPU에 있는지 GPU에 있는지 확인하기 위해서 is_cuda()함수를 사용한다. # CPU에 있는 텐서 t = torch.randn(2,2) t.is_cuda # returns False # GPU에 있는 텐서 t = torch.randn(2,2).cuda() t.is_cuda # returns True Fa..
chapter 4의 내용이다! 정규 언어의 Closure 정규 언어에 대한 주요한 질문들 비정규 언어 판별하기 - pigeonhole principle(비둘기집 원리) 예시로 살펴보자! L = {a^n b^n: n>=0} 이면 L은 정규언어일까? (예제 4.6) 여기에 해당하는 언어는 L = { ƛ, ab, aabb, ... } 등이 있을 것이다. 이 문제를 귀류법으로 접근하면, L이 regular language라면 DFA M = {Q, {a,b}, 𝛿, q_0, F}가 존재할 것이다. i=1,2,3..일 때 𝛿*(q_0, a^i)를 생각하면 i는 무한대로 많을 것인데 M에는 state개수가 유한하다. 그렇다면, 𝛿*(q_0, a^n) = q 𝛿*(q_0, a^m) = q인 서로 다른 n, m이 존재하..
 [Automata][WIP] 정규 언어와 정규 문법
[Automata][WIP] 정규 언어와 정규 문법
이번에는 chapter 3의 내용을 다루려고 한다!.! 정규 표현식 ( Regular Expression ) 정규표현식은 알파벳, 덧셈(+), 곱셈(·), 제곱(*)으로만 이루어져 있다. 덧셈 a+b는 a랑 b로 이루어진 집합에서 뽑아서 쓰는 것이다. a+b = {a, b} 라고 생각하자. 제곱 (a+b)*는 ƛ, a, b, aa, ab, ba, bb, aaa ,,, 등이다. 순서 상관 없다! a*는 0개 이상 반복이다. 예1 ) r = (a+b)*(a+bb) 예2) r = (aa)*(bb)*b 정규 표현식과 정규 언어의 관계 정규 문법 ( Regular Grammar ) 예1) V_0 -> aV_1 V_1 -> abV_0 | b V_0이 시작임
이번 포스팅에서는 Chapter 5에 나오는 내용들을 다뤄보려고 한다! 변수의 6가지 속성 1) names 2) address 3) value 4) type 5) lifetime 6) scope 1) names 대소문자를 가리는가? (Case Sensitivity) C 기반 언어들에서는 대소문자를 가리는데, Readability & Writability 가 안좋아 진다. 특수어 keyword: 특정 문맥에서만 특수 의미를 가짐. ( ex: 변수 이름 ) reserved word: 사용자 정의 이름으로 사용 불가능 ( ex: int, float, ... ) 예약어가 너무 많은 언어는 쓰기 힘들다 ( ex: COBOL의 length, bottom, count 등 ) 길이 너무 짧으면 함축적일수가 없다! C9..
 [ML] PyTorch 기본 함수들
[ML] PyTorch 기본 함수들
텐서(tensor)는 배열(array)이나 행렬(matrix)과 매우 유사한 특수한 자료구조입니다. PyTorch에서는 텐서를 사용하여 모델의 입력과 출력뿐만 아니라 모델의 매개변수를 부호화(encode)합니다. GPU나 다른 연산 가속을 위한 특수한 하드웨어에서 실행할 수 있다는 점을 제외하면, 텐서는 NumPy의 ndarray와 매우 유사합니다. 만약 ndarray에 익숙하다면 Tensor API를 바로 사용할 수 있습니다. list -> tensor data = [[3,5], [10,5]] x_data = torch.tensor(data) numpy array -> tensor np_array = np.array(data) x_np = torch.from_numpy(np_array) tensor -..
 [ML] PyTorch Dataset, DataLoader
[ML] PyTorch Dataset, DataLoader
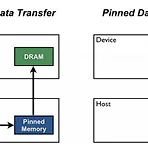
Dataloader DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None) Dataloader class는 batch기반의 딥러닝모델 학습을 위해서 mini batch를 만들어주는 역할을 한다. dataloader를 통해 dataset의 전체 데이터가 batch size로 slice된다. 앞서 만들었던 dataset을 input으로 넣어주면 여러 옵션(데이터 묶기, 섞기, 알아서 병렬처리)을 통해 batch를 만들어준다. 서버에서 돌릴 때..
먼저 시도해볼 방법 git remote set-url origin https://YOURUSERNAME@github.com/USERNAME/REPOSITORY.git 이걸로 remote url을 바꿔본다. 안된다면 밑의 방법을 사용해보자! SSH Key를 이용해서 하는 방법!!! 1. 아래 명령어로 ssh key 생성 $ ssh-keygen 나머지 줄은 엔터 쳐서 생성하면 2. ssh-key 복사 (id_rsa.pub 확인) $ cat ~/.ssh/id_rsa.pub * 꼭 .pub을 써줘야하는 것 같다. 안써주니까 다른 파일이 나왔다! 3. github 키 등록 profile>settings>SSH and GPG keys > New SSH key 클릭 ========== +) profile이 없다는 메..