
오늘은 터미널을 통해서만 다운로드 해보려고 한다. wget https://repo.anaconda.com/archive/Anaconda3-2021.11-Linux-x86_64.sh wget으로 다운받아 준다. https://docs.conda.io/en/latest/miniconda.html 아나콘다 사이트 들어가서 다운로드 할 수 있는 링크를 붙여준것이다. bash Anaconda3-2021.11-Linux-x86_64.sh bash로 실행하면 설치 파일이 열리면서 설치가 된다. 약관에 yes를 쓰고, 설치 주소를 골라주면 된다. (기본적으로는 'home/{username}/anaconda3'로 되는 듯 하다) conda init 으로 설치를 확인하다 +) 만약 conda: command not fou..
passwd root
apt-get install sudo
cat /etc/issue
 [ML] 중심극한정리 (Central Limit Theory, CLT)
[ML] 중심극한정리 (Central Limit Theory, CLT)
정의 서로 독립이며 동일한 분포를 따르는 확률변수 $X_1,X_2,⋯ ,X_n$에 대해, 각각의 평균은 $E(X_i)=\mu$이고 각각의 표준편차는 $\sigma$라 하자. $S_n = X_1 + ... + X_n$ 이면, $\frac{S_n - n\mu} {sigma root(n)}$ 은 N(0,1)을 따른다. 설명 중심 극한 정리는, 어떠한 분포라도 그 분포에서 random하게 N개의 sample을 고르고, 그 평균을 기록하는것을 30번 이상 반복하면 정규분포 모양이 나올 수 있다는 뜻이다. 정규분포가 가지는 두개의 변수인 mean과 variable은 어떤 분포냐에 따라 달라진다. exponential distribution은 mean은 $1/ \lambda$, variance는 $ 1/\lambda..
ls 현재 접근한 폴더의 폴더, 파일 확인 : List Segments ls 뒤에 아무것도 작성하지 않으면 현재 폴더 기준으로 실행 폴더를 작성하면 폴더 기준에서 실행 옵션 -a : .으로 시작하는 파일, 폴더를 포함해 전체 파일 출력 -l : 퍼미션, 소유자, 만든 날짜, 용량까지 출력 -h : 용량을 사람이 읽기 쉽도록 GB, MB 등 표현. `-l`과 같이 사용 ls ~ ls ls -al ls -lh echo Python의 print처럼 터미널에 텍스트 출력 echo “hi” echo `쉘 커맨드` 입력시 쉘 커맨드의 결과를 출력. ` : 1 왼쪽에 있는 backtick echo `pwd`
네이버 부스트캠프 AI Tech 3기 강의를 듣는 과정에서 작성된 포스트입니다. 강의 내용을 저만의 언어로 재해석 했습니다. MLflow를 공부하면서 버전관리, 코드 저장 등의 프로젝트 관리를 해준다는 점에서 머신러닝계의 깃허브 처럼 느껴졌다. 중요한 기능들 1 ) 실험 기록하기 실험을 정의하고, 실험을 실행할 수 있다. 각 실행해서 사용한 소스 코드, 하이퍼 파라미터, 부산물(Chart Image)등을 저장해준다. seed, num_round, gamma 등의 변수를 기록해준다. 2 ) 모델 저장소에 등록하기 깃헙처럼 모델의 저장 버전을 관리해준다. 공유가 쉬워진다. 3 ) 모델 서빙 모델 저장소에 등록된 모델에 input을 넣었을 때 나오는 output을 REST API 형태로 사용할 수 있다. Ex..
 [ML] epoch, batch size, iter의 의미
[ML] epoch, batch size, iter의 의미
epoch : 한 번의 epoch는 인공 신경망에서 전체 데이터 셋에 대해 forward pass/backward pass 과정을 거친 것을 말함. 즉, 전체 데이터 셋에 대해 한 번 학습을 완료한 상태 epochs = 40이라면 전체 데이터를 40번 사용해서 학습을 거치는 것입니다. ▶ 우리는 모델을 만들 때 적절한 epoch 값을 설정해야만 underfitting과 overfitting을 방지할 수 있습니다. epoch 값이 너무 작다면 underfitting이, 너무 크다면 overfitting이 발생할 확률이 높은 것이죠. batch size, iteration : 한 번의 batch마다 주는 데이터 샘플의 size. 여기서 batch(보통 mini-batch라고 표현)는 나눠진 데이터 셋을 뜻하..
"%02d" 에서 0 : 빈자리를 0으로 채운다, 2 : 2칸을 차지한다는 뜻이다
nn.Linear은 행렬과 같다. nn.Linear을 통해서 행렬을 곱해서 tensor의 size()를 바꿀 수 있다. import torch from torch import nn X = torch.Tensor([[1, 2], [3, 4]]) # TODO : tensor X의 크기는 (2, 2)입니다 # nn.Linear를 사용하여서 (2, 5)로 크기를 바꾸고 이 크기를 출력하세요! m = torch.nn.Linear(2, 5) output = m(X) print(output.size())
 [ColorSpace] RGB / HSL / hex / CMYK
[ColorSpace] RGB / HSL / hex / CMYK
아직 해결하지 못한 질문 Q ) rbg랑 HSL이랑 호환이 되는가? 항상 2개 이상의 cone이 반응하게 된다. -> 어떤 값은 마이너스여야 한다?? 그래서 (창의의) brightness를 추가함. RGB = 빛의 3원색 0 ~ 255까지. 디스플레이로만 보이는 프로젝트 시. RGB로 작업해서 인쇄시 탁해질 수 있다. CMYK = 색의 3원색 실물 인쇄가 필요할 때. HSL ( HSV라고도 부른다 ). Hue(색조) : 빨강, 파랑, 초록 등 색상으로 생각하는 부분 빨강에서 보라색까지 있는 스펙트럼에서 0-360으로 표현 Saturate(채도) : 무채색과의 차이 선명도라고 볼 수 있음 (선명하다와 탁하다.) Lightness(광도) (value) : 색상의 밝기 1. Color - 결국 사람이 보는 c..
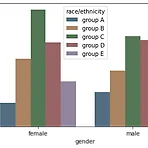 [Visualization] Seaborn 사용법
[Visualization] Seaborn 사용법
Intro Matplotlib와 어떤점이 다를까 싶을 수도 있는데 다음 링크에 잘 설명되어 있다 실제 사용해본 느낌으로는, matplotlib이 가장 기초적이고 모든 부분이 custom 가능하지만 너무 신경써야할 부분이 많았고, 반대로 seaborn은 디자인과 사용이 매우 쉬웠지만 커스텀을 하기에는 어려웠다. 메모리 사용량도 seaborn이 더 높다고 링크에 설명되어 있었다. Install and Import ! pip install seaborn import seaborn as sns 종류 - API reference Relational plot relplot, scatterplot, lineplot Distribution displot, histplot, kdeplot, ecdfplot, rugplo..

 [Matplotlib] Bar, Line, Scatter Plot 그리기
[Matplotlib] Bar, Line, Scatter Plot 그리기
네이버 부스트캠프 AI Tech 3기 강의를 듣는 과정에서 작성된 포스트입니다. 강의 내용을 저만의 언어로 재해석 했습니다. Matplotlib말고도 Seaborn, Plotly, Bokeh, Altair 등의 다양하고 친절한 시각화 라이브러리가 존재한다. 그럼에도 불구하 Matplotlib가 범용성이 제일 넓고, base가 되는 라이브러리라서 정리해보고자 한다. Import 하기 import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt print(f'numpy version : {np.__version__}') # version check print(f'matplotlib version : {mpl.__version__}')..
https://better-together.tistory.com/282

 [ML] Pandas(Python Data Analysis Library)를 사용해보자
[ML] Pandas(Python Data Analysis Library)를 사용해보자
고성능 array 계산 라이브러리인 numpy와 통합하여, 강력한 “스프레드시트” 처리 기능을 제공하는 판다스에 대해서 좀 더 알아보자! 파이썬계의 엑셀이라고 생각하면 된다. panel data 의 줄임말인 pandas는 파이썬의 데이터 처리의 사실상의 표준인 라이브러리입니다. pandas는 파이썬에서 일종의 엑셀과 같은 역할을 하여 데이터를 전처리하거나 통계 처리시 많이 활용하는 피봇 테이블 등의 기능을 사용할 때 쓸 수 있습니다. pandas 역시 numpy를 기반으로 하여 개발되어 있으며, R의 데이터 처리 기법을 참고하여 많은 함수가 구성되어 있거 기존 R 사용자들도 쉽게 해당 모듈을 사용할 수 있도록 지원하고 있습니다. 설치하기 pip install pandas csv파일 불러오기 이미 데이터 ..
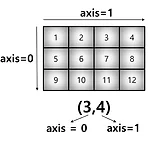 [ML] numpy 함수들
[ML] numpy 함수들
1. array 생성 np.array([1,4,5,6], float) # ndarray 타입으로 생긴다. 이미 pyTorch의 Tensor로 정의되어 있다면 바로 바꿀 수도 있다. embeddings_t = torch.Tensor(np.ones((2, 2))) embeddings_numpy = embeddings_t.numpy() numpy는 하나의 데이터 타입만 넣을 수 있는거 기억하자! 2. array 모양 받아오기, 타입 확인하기, 크기 확인하기 array.shape array.dtype array.nbytes 3. shape 바꾸기 array.reshape(8,) array.reshape(-1,2) # -1은 안쓰는것처럼 size를 기반으로 자동 설정 해준다. array.flatten() 4. i..
import torch.nn as nn import torch.nn.functional as F class Model(nn.Module): def __init__(self): super(Model, self).__init__() self.conv1 = nn.Conv2d(1, 20, 5) self.conv2 = nn.Conv2d(20, 20, 5) def forward(self, x): x = F.relu(self.conv1(x)) return F.relu(self.conv2(x)) 왜 super(Model, self).__init__()을 써줄까? you need the super() call so that the mn.Module class itself is initialised. IN Python s..
index_select >>> x = torch.randn(3, 4) >>> x tensor([[ 0.1427, 0.0231, -0.5414, -1.0009], [-0.4664, 0.2647, -0.1228, -1.1068], [-1.1734, -0.6571, 0.7230, -0.6004]]) >>> indices = torch.tensor([0, 2]) >>> torch.index_select(x, 0, indices) tensor([[ 0.1427, 0.0231, -0.5414, -1.0009], [-1.1734, -0.6571, 0.7230, -0.6004]]) >>> torch.index_select(x, 1, indices) tensor([[ 0.1427, -0.5414], [-0.4664, -..
numpy의 random 함수들을 정리해보려고 한다! numpy np.random.uniform(시작, 끝, 개수) # 균등분포 np.random.normal(시작, 끝, 개수) # 정규분포 torch torch.randn torch.randint(5, (10,5)).shape # torch.Size([10,5]) torch.randint torch.randint(5, (10,5)).shape # torch.Size([10,5]) low는 명시하지 않으면 0이고, high와 size를 넣는다.
내 시간 돌려줘용
GIL이란 Global Interpreter Lock의 약자로 파이썬 인터프리터가 한 스레드만 하나의 바이트코드를 실행 시킬 수 있도록 해주는 Lock입니다. 하나의 스레드에 모든 자원을 허락하고 그 후에는 Lock을 걸어 다른 스레드는 실행할 수 없게 막아버리는 것이다. 운영체제에서 배운 lock과 동일하다! 당연히..존나 느리다... 파이썬이 처음 개발되던 시기는 코어가 하나이던 컴퓨터가 대부분이므로 이런 선택을 했지만, 요즘 시대에는 미친듯한 단점이다..!!! PriorityQueue 모듈같은 경우에는 GIL이 아니라고 하지만, 아직까지 많은 부분에 남아있다고 한다... [출처] 파이썬 알고리즘 인터뷰(박상길) p.278