
크게 Node level, Edge level, Subgraph level, Graph level 4가지로 나누어서 본다. Node Level ex1) Protein Folding Edge Level Recommender System에서 User-Item간의 edge 추측하기 ex1) PinSage ex2) Drug Side Effect 약을 같이 복용했을때의 부작용 예측하기 Node = 약&단백질, Edge = 부작용 Subgraph Level ex) Traffic Prediction Node= Road Segment Edge = connectivity between road segments Prediction = Time of Arrival Graph level ex) Drug Discovery: g..
from Stanford CS224W - event graphs, computer networks, disease pathways, food webs, particle networks, underground networks, social networks, economic networks, communication networks, citation networks, internet, networks of neuron, knowledge graphs, regulatory networks, scene graphs, code graphs, molecules, 3D shapes
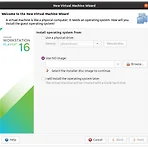 [Ubuntu] 우분투에 VMWare Workstation Player로 Windows 10 설치하기
[Ubuntu] 우분투에 VMWare Workstation Player로 Windows 10 설치하기
https://customerconnect.vmware.com/en/downloads/details?downloadGroup=WKST-PLAYER-1624&productId=1039&rPId=91446 여기에서 VMware Workstation 16.2.4 Player for Linux 64-bit 를 다운로드 받는다. .bundle 파일은 sudo sh ~~.bundle 을 통해서 실행 시킨다. 우분투 프로그램 리스트에 생긴 VMWare Workstation을 실행하고 설치를 진행해준다. Create a New Virtual Machine > Use ISO Image로 추가해준다.
KDD ICLR ICML NeurlPS WWW WSDM
 [CS] 첫 논문을 쓰면서 배운것(IEEE Conference양식, Latex사용법)
[CS] 첫 논문을 쓰면서 배운것(IEEE Conference양식, Latex사용법)
최근에 네트워크를 공부하며 배운 얕은 지식으로 아주 간단한 3-page Survey paper을 썼다. conference에 제출도 완료 했다. 논문을 읽은적은 많았지만, 작성한 것은 처음이었는데 생각보다 Latex사용법이나 기본적인 작성법들을 잘 모른다는걸 느꼈고 연구실 박사과정 분께서 지도해주신 내용을 잊지 않기 위해 기록해두려고 한다. 💪🏻 참고로 분야마다 룰이 많이 다르다는걸 느꼈다. 나는 Computer Science의 Network 분야를 기준으로 작성한거라고 생각해주면 좋겠다. 작업하는 tool은 overleaf https://www.overleaf.com/project 에서 작업을 하고, 공유를 해서 썼다. overleaf는 online editing tool이고, 동시 접속 및 채팅, c..
def combine(n, k): results = [] def dfs(elements, start, k): if k==0: results.append(elements[:]) for i in range(start, n+1): elements.append(i) dfs(elements, i+1, k-1) elements.pop() dfs([], 1, k) return results N, M = map(int, input().split()) for i in combine(N, M): print(*i)
 [Python] 백준 15649번 - N과 M (1)
[Python] 백준 15649번 - N과 M (1)
def permute(N, M): elements = [i for i in range(1, N+1)] results = [] prev_elements = [] def dfs(elements): if len(elements) == N-M: results.append(prev_elements[:]) for e in elements: next_elements = elements[:] next_elements.remove(e) prev_elements.append(e) dfs(next_elements) prev_elements.pop() dfs(elements) return results N, M = map(int, input().split()) for i in permute(N, M): print(*i) 기억..
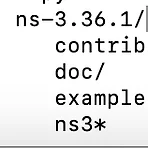 [Linux] 파일 뒤에 붙는 *은 뭘까?
[Linux] 파일 뒤에 붙는 *은 뭘까?
ns3*, test.py*처럼 *이 붙은 파일이 있다. -F After each file name, put one of: + A slash (/) if the file is a directory or a symbolic link to a directory. + An asterisk (*) if the file is executable; + An at-sign (@) if the file is a symbolic link to a file; + A vertical bar (|) if the file is a fifo. *은 실행 가능한 파일이라는 뜻이다.
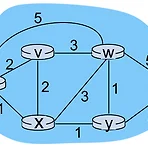 [Algo] Bellman-Ford Algorithm(벨만-포드 알고리즘)
[Algo] Bellman-Ford Algorithm(벨만-포드 알고리즘)
이번에 배워볼 알고리즘은 벨만 포드 알고리즘(Bellman-Ford Algorithm)이다. 이 알고리즘 또한 이전에 배운 다익스트라 알고리즘처럼 그래프에서 한 정점에서 다른 모든 정점으로 가는 최단 경로를 구할 수 있는 알고리즘이다. 벨만 포드 알고리즘은 다익스트라 알고리즘보다 시간이 더 걸리지만 음의 간선이 존재해도 최단 경로를 찾을 수 있는 알고리즘이다. 벨만 포드 알고리즘은 다이나믹 프로그래밍이라고 할 수 있다. 그 이유는 매번 저장해놓은 최소 비용을 이용해서 새로운 최소 비용으로 갱신하기 때문이다. 벨만 포드 알고리즘이 다익스트라 알고리즘보다 시간이 오래 걸리는 이유는 다익스트라는 최소 비용을 가지는 간선만 우선적으로 뽑으면서 경우의 수를 줄여가며 비용을 갱신하였다. 하지만 벨만 포드 알고리즘..
 [ChromeExtensionDev] React, TypeScript로 github.com에서 추천해주는 Chrome Extension 만들기
[ChromeExtensionDev] React, TypeScript로 github.com에서 추천해주는 Chrome Extension 만들기
부스트캠프 AI Tech 3기 추천시스템 최종 프로젝트를 진행하며 개발했습니다. 이 글은 Chrome Extension을 만드는 방법에 대해서 소개하고, 주의해야 할 사항을 설명하는 포스팅입니다. Intro Chrome Extension을 개발하며 겪었던 보안 이슈에 대해서는 타 포스팅에 적었는데, 개발하는 전반적인 방법이나 공부한 것들에 대해서 정리하고 주의사항도 간단하게 적기 위해서 포스팅을 쓴다. BoilerPlate Github 에 있는 BoilerPlate를 사용해서 개발했다. 이 BoilerPlate의 Readme를 참고하면 사용법이 나와있는데, git clone을 받은 후 npm start로 빌드할 수 있고 코드를 수정하고, save하면 바로 또 빌드가 된다. 처음에 개발하기에 너무 막막해서..
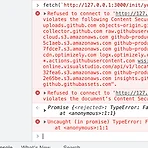 [ChromeExtensionDev] "Refused to connect to '{URL}' because it violates the document's Content Security Policy." 해결하기
[ChromeExtensionDev] "Refused to connect to '{URL}' because it violates the document's Content Security Policy." 해결하기
이 문제때문에 무려 이틀을 헤맸다..ㅠㅠ 상황 설명 Github.com에서 사용자가 Repository에 Like를 눌렀을 때, chrome extension의 background.tsx파일에서 우리쪽 서버의 API(GET)를 콜 해주려고 했다. 그런데 이 API를 콜하면 정상적으로 실행이 되지 않았다. Postman으로 API를 실행하면 정상 동작 했고, 호출하는 URL도 로그를 찍어봤을 때 정상적이었기 때문에 크롬 단에서 차단을 하고 있다는 의심을 하기 시작했다. 해결 방안 모색하기 Chrome의 Network탭에서 확인을 했을 때 ERR_CERT_INVALID 로 나와서 처음에는 https인증문제를 의심했다. 또한 CORS문제를 의심했었는데, 처음에는 크롬 Network탭에서의 에러 메세지가 Unc..
리액트를 그때 그때 배워서 쓰다 보니 이런 에러를 자주 마주하곤 한다. '{ username: any; repoid: any; }' 형식은 'IntrinsicAttributes & { children?: ReactNode; }' 형식에 할당할 수 없습니다. 'IntrinsicAttributes & { children?: ReactNode; }' 형식에 'username' 속성이 없습니다.ts(2322) 이 문제는 뷰를 만드는 쪽에서 파라미터를 제대로 안써줘서 발생할 가능성이 높다. 나 같은 경우에는 뷰를 만들 때 파라미터들 사이에 콤마를 써줘서 이 에러가 발생하기도 했었다. 밑의 코드를 보고 혹시 빼먹은 파라미터가 없는지 타입은 명시해줬는지 콤마를 쓰지 말아야 하는 곳에서 콤마를 쓰진 않았는지 엔터를 안..
보호되어 있는 글입니다.
pickle 모듈 사용하기! 저장하기 : pickle.dump import pickle name = 'james' age = 17 address = '서울시 서초구 반포동' scores = {'korean': 90, 'english': 95, 'mathematics': 85, 'science': 82} with open('james.p', 'wb') as file: # james.p 파일을 바이너리 쓰기 모드(wb)로 열기 pickle.dump(name, file) pickle.dump(age, file) pickle.dump(address, file) pickle.dump(scores, file) 파일에서 읽어오기 : pickle.load import pickle with open('james.p', ..
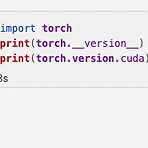 [DL] torch-geometric 설치하기 (torch-sparse 에러 해결 포함)
[DL] torch-geometric 설치하기 (torch-sparse 에러 해결 포함)
일단 가상환경 위 혹은 도커 위에서 설치해야 한다. 공식 문서에서는 root user에서 설치하지 말라고 한다. anaconda로 설치하기 현재 자신의 pytorch 버전이 1.10 이상이고, CUDA버전이 10.2 이상이라면 anaconda를 통해서 설치하는것을 추천한다. conda install pyg -c pyg 그 이하의 버전이라면 pip wheel을 통해서 설치해야 한다. (조금 복잡함) pytorch와 CUDA버전을 올리고 싶을 수 있다. 이때 주의해야 할 사항들은 다음과 같다. 1. gpu의 CUDA버전과 torch의 CUDA 버전이 같은지 확인한다. nvidia-smi에서 나온 CUDA버전과 $ print(torch.version.cuda) 에서 나온 버전이 같은 것이 좋다. 아니면 예상치..
def printme(func): def new_function(*args, **kwargs): print("Name:", func.__name__) print("Positional Arguments:", args) print("Keyword Arguments:", kwargs) result = func(*args, **kwargs) print("Result:", result) return result return new_function @printme def add_ints(a, b): return a + b add_ints(1, 2) Name: add_ints Positional Arguments: (1, 2) Keyword Arguments: {} Result: 3
 [ML] Azure AutoML을 사용해보기
[ML] Azure AutoML을 사용해보기
네이버 부스트캠프 AI Tech 3기 강의 중 최영선 멘토님의 특강을 듣는 과정에서 작성된 포스트입니다. 강의 내용을 저만의 언어로 재해석 했습니다. AutoML이란? ML의 대부분의 과정을 자동화해주는 툴이다. 아마존, 구글클라우드, 마이크로소프트에서 모두 AutoML 관련 프레임워크를 만들고 있다. 데이터 분석, 파라미터 튜닝 등 정말 많은 부분을 자동화해주는 갓갓 프레임워크이다. AzureML이란? Azure for Students를 구독하면 한정된 기능으로 Azure을 무료로 이용할 수 있다. (매년 학생 계정으로 재인증을 해야한다는 단점이 있긴 하다.) 학교 microsoft 계정이랑 연동되어서 쉽게 가입할 수 있었다. 집 주소를 입력해야 하고 핸드폰 번호 인증을 받아야 한다. 영어로 설정해서 ..
https://github.com/danielgatis/rembg
한장 Image.open으로 Image 객체로 받아오고, np.array로 array로 만들고 plt.imshow로 보여주기. img_path = f'어쩌구.jpg' img = np.array(Image.open(img_path)) plt.figure(figsize=(16,8)) plt.imshow(img) 4장 묶어서 plt.subplots함수로 만들어주고, 각각에 imshow와 title 달아주기 tight_layout으로 완성 n_rows, n_cols = 2, 2 fig, axes = plt.subplots(n_rows, n_cols, sharex=True, sharey=True, figsize=(8, 8)) axes[0][0].imshow(img) axes[0][0].set_title(f'Ori..
pip install wandb wandb login key를 wandb.ai에서 복사해서 붙여준다. import wandb 코드의 첫 부분에 써준다. wandb.init() 혹시 프로젝트 이름과 id를 명시하고싶다면 wandb.init(project='Machine-Learning-Project', entity='jonyejin') 이렇게 써주면 된다! argparse가 선언이 되어있고, parse_args()로 args를 정의했다면 다음과 같이 wandb.config.update를 해준다. def main(): # Training settings parser = argparse.ArgumentParser(description='PyTorch MNIST Example') ... args = parser..
import cv2를 했는데 """ cannot open shared object file no such file or directory ImportError: libGL.so.1: cannot open shared object file: No such file or directory """ 에러가 난다면 libgl이 서치가 안되어서 실행이 안될 확률이 높다. apt-get install libgl1-mesa-glx pip install opencv-python 하니까 잘 되는 모습을 볼 수 있다. 만약 ModuleNotFoundError: No module named 'cv2' 에러가 뜬다면 pip install opencv-python 으로 설치해주면 된다.
 Jupyter Notebook 단축키 정리
Jupyter Notebook 단축키 정리
Command Mode a : above에 셀 추가 b : below에 셀 추가 c : 셀 copy v : 셀 paste x: 셀 cut d, d : 셀 삭제 방향키로 이동 L: 줄번호 보이게, 안보이게 Edit Mode enter: 수정 모드로 진입 ctrl + enter: 현재 셀 실행 shift + enter: 현재 셀 실행하고 다음 셀로 넘어가기 [출처] https://taptorestart.tistory.com/entry/Jupyter-Notebook-주피터-노트북-단축키shortcuts-정리
 [ML][Anaconda] 아나콘다 환경을 복사하는 법
[ML][Anaconda] 아나콘다 환경을 복사하는 법
1. yml 파일을 통해서 복사하기 conda env export -n {env_name} > env.yml 하고 vi env.yml 로 파일을 확인해보면, 이렇게 conda를 통해서 설치된 목록이 보인다. 새로운 환경을 만들 때, conda env create -f env.yml 로 생성하면 된다. 내가 자주 쓰는 env.yml 파일을 공유하려고 한다. 내용 > 더보기 name: venv channels: - pytorch - conda-forge - defaults dependencies: - _libgcc_mutex=0.1=main - _openmp_mutex=4.5=1_gnu - absl-py=1.0.0=pyhd8ed1ab_0 - aiohttp=3.7.4.post0=py38h7f8727e_2 - ..
https://happycloud-lee.tistory.com/185